在【海量資料分析與精準情報決策】一文中,我們討論海量資料(Big Data)定義、應用與商機,並提出如何在情報理論架構下,重新建立海量資料分析的新思維。本文進一步從情報循環(Intelligence Cycle)架構,提出海量資料分析五部曲。
在【情報週期管理意涵與方法】一文中,我們曾提出情報理論與情報循環架構,包括指導(Direction)、蒐集(Collection)、處理(Processing)與運用(Use)。從國際資訊大廠Oracle定義[3],海量資料分析循環包括擷取(Acquire)、組織(Organize)、分析(Analyze)與決策(Decide)等四步驟。運用海量資料的目的與情報循環之目的一樣,均是用於支援決策並找出新商機。對造兩者間關係,蒐集步驟對應到擷取步驟、處理步驟對應到組織與分析步驟、運用步驟對應到決策步驟。結合兩者,可以得到海量資料分析五部曲,如圖一所示。
指導即是規劃(Plan),規劃海量分析所要擷取標的、組織方式、分析模式與支援決策內容。指導是海量資料分析的關鍵。資訊處理要避免GIGO(garbage in, garbage out)的關鍵就在規劃階段。在情報理論實踐中,規劃與指導通常由資深情報官負責,在海量資料分析中亦然,若沒有深厚的產業實務經驗,將無法取得有意義的結果,更遑論分析資料後所得的洞見(Insight)。
指導步驟的產出(Output)是擷取與組織步驟的起點。鑑於海量資料分析通常包括異質(Hybrid)資料,因此資料擷取,組織與儲存,需要有特殊考量。需要說明,若以情報理論來說,組織步驟通常與分類結構相關,如何建立易於分析的分類結構與資料,是海量分析效能的關鍵。
分析是海量資料處理的另一關鍵。簡易的分析是包括找出所定義範疇不同物件的關係,例如一個著名的範例是Wal-Mart透過帳單分析,找出啤酒、紙尿布與星期五銷售之關連性,透過將啤酒與紙尿布放在一起販賣,提升了啤酒的銷售量。在此案例中,範疇是清楚的(啤酒、紙尿布、星期五與帳單金額)。另一個較為複雜的則是不易定義範疇的分析,其分析模式與工具也尚在開發中。畢竟,要”知道”哪些”自己不知道”的,原本就是非常困難。
不論是指導步驟或是擷取、組織與分析步驟的目的均是要能決策,因此指導是否有意義,分析結果是否能產生價值,其最終的判斷準則均要能用於決策。以現有海量資料分析方法論中,均集中在擷取、組織與分析步驟,其實真正關鍵的是決策與組織。決策與組織步驟的好壞影響了海量資料分析價值的八成結果。
若從情報循環角度論,其實海量資料分析步驟應如圖一(b)所示,步驟分別為1.決策、2.指導、3.擷取、4.組織、5.分析,之後再回到1.決策結果之銜接。換言之,海量資料分析第一個要問的問題是,此海量資料分析是要滿足哪些決策,根據這些決策,要規劃哪些資料蒐集與分析內容。如此思維方式海量資料分析的正確觀念。
最後,在【PDCA環與回饋控制系統】一文中,我們曾討論PDCA環(戴明環)與回饋控制系統之關連性,資訊處理與支援決策等自然與社會科學的核心在於重複性與方法精進。如何在此循環之觀念中,持續修正決策釐清、指導模式、擷取方法、組織機制與分析模式,方是海量資料分析能否真正產生價值的關鍵。
當然,下次當有人推銷你海量分析工具時,也要記得要”多問一句”,你這工具的目的為何?可以支援哪些原本無法處理的決策?多瞭解工具背後的原因與需求,才能找出你真正需要的工具,並且是有用的工具。從上述說明中也可看出,海量資料分析的關鍵仍是產業深厚知識(Domain Know-how),即洞見,缺少了此洞見,將很難避免落入GIGO的窘境。(1250字;圖1)
圖一 海量資料分析五部曲
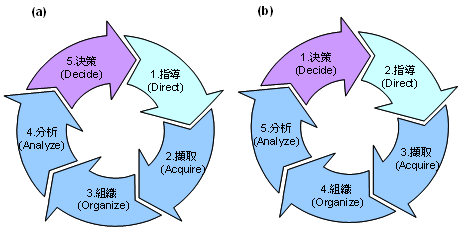
Source:科技政策研究與資訊中心—產業資訊室整理,2013/03
參考資料:
- 海量資料分析與精準情報決策, http://iknow.stpi.narl.org.tw/post/read.aspx?postid=7687
- 情報週期管理意涵與方法, Read.aspx?PostID=8482
- Robert Stackowiak, An Integrated Big Data & Analytics Infrastructure, http://www.nist.gov/itl/ssd/is/upload/Oracle_NIST_Stackowiak_v061412.pdf
- PDCA環與回饋控制系統, Read.aspx?PostID=2956
--------------------------------------------------------------------------------------------------------------------------------------------