
微軟應用Transformer模型開發之生成式AI「程式碼自動完成」專利
科技產業資訊室(iKnow) - 陳家駿、許正乾 發表於 2023年9月7日

圖、微軟應用Transformer模型開發之生成式AI「程式碼自動完成」專利
針對ChatGPT,Google於2019年10月22日,獲得美國專利局核准之一件專利案號為US 10,452,978 B2,其標題為「基於注意力序列轉導神經網路」(Attention-based sequence transduction neural networks)之發明專利[1](以下稱’978專利),目前’978專利簡單同族專利[2]數量有38件並分佈在13國家,而被引用專利數量為11件,且還有對應發表過的原始論文「Attention Is All You Need」[3]。本刊之前已分析過該篇’978專利之相關介紹(Google Transformer模型專利 – ChatGPT自注意力機制之重要推手)。
Google固然引領風潮率先推出Transformer模型專利,但商場上第一波ChatGPT成功拔得頭籌的卻是微軟,微軟於2019年向軟體開發商OpenAI投資10億美元,由於持續看好OpenAI旗下的聊天機器人ChatGPT的前景,隨著2022年11月ChatGPT問世後使用熱度橫掃全球,使得微軟在2023年1月宣布擬再加碼投資100億美元。對於此,市場一度認為微軟終於有機會在這波AI軍備競賽中,打敗軟體業的巨頭Google,使得微軟的市值在同年2月突破2兆美元。也許,大家會好奇,OpenAI與微軟在生成式AI的專利佈局狀況又是如何?
筆者試圖尋找OpenAI是否也有相關生成式AI的相關專利,不過截至目前,發現OpenAI似乎沒有申請過相關專利,也許這跟富比士(Forbes)的推測有關:OpenAI的早期本身就是非營利組織[4]。正因為初期的OpenAI並非以營利為目的,所以在專利申請方面較不在意。
微軟的’984專利之Transformer模型的應用
既然暫未發現OpenAI有生成式AI相關專利,那麼就來找OpenAI的最大金主微軟,看看微軟對於生成式AI或Transformer模型的相關專利有哪些?基於與上次Google篇的同樣條件去檢索美國專利資料庫,發現微軟不僅相關專利的數量不似Google來得多,而且在質量上似乎也不如Google。筆者最後篩選出的數十篇相關專利,然後再利用ChatGPT快速針對幾十篇的專利說明書做摘要後,決定就來討論其中一篇發明專利案號為US 11,262,984 B2之「多語言程式碼行自動完成系統」(Multi-Lingual Line-of-code Completion System)[5](以下稱’984專利)。’984專利在2019年11月11日申請,並在2022年3月1日獲准,從申請到獲准共歷時28個月。
之所以選定’984專利來做討論,是因為在微軟所有生成式AI或Transformer模型的專利中,它具有以下特點:(1)簡單同族專利數量5件並分布在3個國家,而被引用的專利數量有19件(包含已獲證與其獲證之前的申請案);(2)其係完全基於Transformer模型而做的衍生應用;以及,(3)可能與微軟近來爆紅的Copilot產品功能有關。其中,針對第(2)點,微軟’984專利在實施例中,雖然洋洋灑灑用自己的方式大篇幅描述Transformer模型,但本質上卻與Google的原始論文或Google的’978專利所描述的Transformer模型的技術原理一樣,差別在於微軟在’984專利中主張,透過應用Transformer模型,開發人員在「部分形成的程式碼行」[6](partially-formed line-of-code)[7]編寫程式時,可以「自動完成」接續未完成的程式碼撰寫。
傳統的程式碼行自動完成(line-of-code completion)功能的缺點
什麼是程式碼自動完成?簡單來說,程式碼自動完成是一種軟體開發工具的其中一項功能,能夠在程式碼編輯過程中提供智慧化的建議和自動接續填寫功能,以提升程式開發人員的開發速度。程式開發人員於撰擬程式時,通常會有幾個可能,如圖1所示,像是筆者常用R語言的整合開發環境(Integrated Development Environment,簡稱IDE)RStudio介面的一部分,其本身就是一個程式碼編輯器,只是不含Transformer模型的功能。圖1所顯示的是撰寫程式碼時,在IDE介面呈現完全無誤的狀態,其中箭頭所指示的數字就是所謂的「程式碼行」(line-of-code)。反之,在開發人員撰寫程式碼的過程中,也有可能發生一種情況,亦即如執行某程式碼行發生語法結構上的錯誤時,此時IDE介面就會出現錯誤提示,以提醒開發人員需要針對該程式碼行除錯(debug),如圖2所示。
圖1、程式碼行呈現完全無誤的狀態
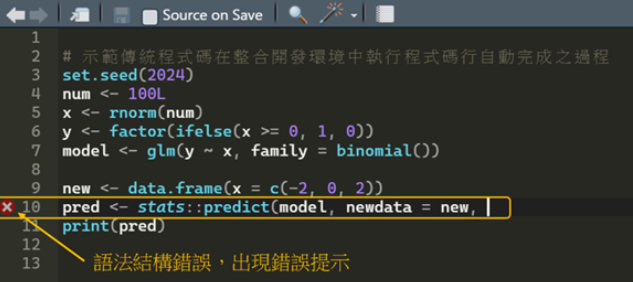
圖2、執行程式碼行發生語法結構錯誤時,出現錯誤提示
再來圖3則是開發人員撰寫程式碼過程中,IDE會在其背景偵測每一行的程式碼行,然後對應彈出一項清單,清單中自動出現可能的相關函數、變數、方法、關鍵字或引數(argument)等候選提示或建議,以協助開發人員手動選擇適合的建議,以接續未完成的程式碼撰寫,而這樣的動作就稱為「程式碼行自動完成」(line-of-code completion)。還有另一種狀況,開發人員透過按下tab鍵後自動補齊程式碼,例如在IDE介面已有個名為model的變數名稱,當再次輸入mod,然後再按下tab鍵後,IDE將自動完成該變數名稱model。
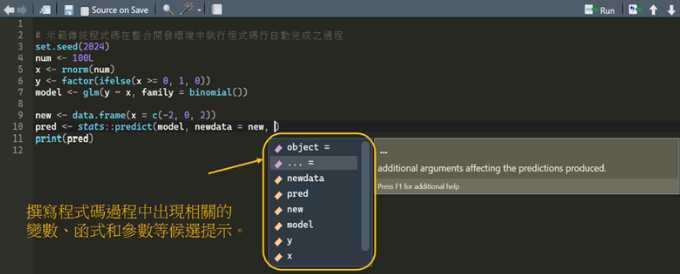
圖3、撰寫程式碼過程中出現候選提示
然而,傳統的程式碼行自動完成功能,雖然可協助開發人員在編寫程式碼時,更快地輸入有關的函數、變數、方法、關鍵字或引數,但它卻無法「推理」多行程式碼之間的邏輯為何。以圖1、3為例,圖1的第10行正確無誤的語法結構,亦即「pred <̶ stats::predict(model, newdata = new, type = “response”)」,才是筆者真實想要編寫的程式碼。然而,回到圖3所示,筆者做了一個實驗,刻意將引數「type = “response”」字段予以刪除,試試看會出現什麼樣的提示或警告,結果發現IDE介面所彈出的所有候選提示,例如”object =”、”… = ”、”newdata”、”pred”、…等很多提示都跟筆者真實想要輸入的字串「type = “response”」無關,因此最後還是得靠過去程式撰寫經驗,將「type = “response”」予以手動輸入完成第10行程式碼行的撰寫。由此可見,傳統的程式碼行自動完成功能,尚無法真正推理出多程式碼行之間的涵義,這就是它的缺點。
微軟’984專利利用Transformer模型改進習知程式碼行自動完成功能
微軟在’984專利中宣稱,其程式碼行自動完成功能係透過Transformer模型訓練而得以改進習知的缺點,甚至為了降低Transformer模型的訓練時間,還引入「多頭自注意力層」(multi-head self-attention layer)。至於大型的訓練資料集,則來自如GitHub或其他程式碼儲存庫中的各種程式語言(例如C、Java、Python、C++)的原始碼(source code),而訓練資料集中的各原始碼與註解,都會被編碼成數值型向量。這些數值型向量是由斷詞(token)[8]和/或子斷詞(subtoken)組成的序列。在程式語言中常用的元素被編碼為斷詞,而較不常出現的元素,則被編碼成一些組合的字元為子斷詞。這樣的作法,基本上就是利用了Google在原始論文「Attention Is All You Need」與其獲證的專利中所提及的「詞嵌入」(word embedding)[9]與「位置嵌入」(positional embedding)[10]等技術,如此不僅可以減少大型詞彙的儲存,而且還有更好的準確度。
以上所述的斷詞,在自然語言處理的過程是一個很重要而基礎的工作,例如「transformer model <\n>」這樣的一序列,可被切割為trans、former、model與”\n”(此稱為換行符,對於程式編輯器而言也是一個字元,通常發生於程式碼行的尾端(end-of-line)),而其對應的編碼可為[43678, 67971, 14560, 98765]之數值型向量。這樣編碼後的結果就稱為4個token[11],以上的對於理解接下來要談的’984專利的發明內容非常重要。
微軟在’984專利中的獨立項共有3項,分別為獨立項1的系統項、獨立項9的方法項,以及獨立項15的裝置項。雖然’984專利的標題只提到系統,但從’984專利的實施例與代表圖的技術揭露來看,其主要的技術仍是演算方法的保護,故以下就以獨立項9與其附屬項等方法項,做一些重要技術特徵的說明。
獨立項9揭露一種方法,其包含[12]:
- 在IDE編寫程式碼過程中,IDE的編輯器,會檢視各斷詞被輸入至一未完成的程式碼行(line-of-code)之狀況;
- 遞迴式(iteratively)執行一波束搜尋(beam search),以產生多個斷詞候選(token candidates),並陸續完成程式碼行的撰寫,其中該波束搜尋是從具有注意力機制的解碼器,所產生的多個斷詞機率中對應生成包含多個字串所組成的一候選清單;
- 合併該候選清單中的多個字串,使該多個字串成為一候選序列;以及
- 一旦在IDE中偵測到某一符號字元,就輸出至少一候選序列。
以上所述的波束搜尋是一種搜尋演算法,通常用於生成式模型,特別是在自然語言處理等序列生成之任務,它在每個樹狀節點都代表著,經由Transformer模型的機率分佈,所生成的每一個斷詞或子斷詞,藉此從眾多的斷詞候選中找出最有可能的前k個斷詞。
簡言之,關於以上所述的具體範例,’984專利給出如圖4所示,其顯示開發人員在IDE介面上,正在編寫某一程式碼行(標號702中的第36行)時,IDE的編輯器偵測到「=」符號(即前述(d)中所述的「符號字元」),就對應彈出一候選清單(標號704)。該候選清單(標號704)包含5個候選序列(標號706-714),而這5個候選序列的排序,是依據由大而小的機率一一往下陳列出。此外,各候選序列中,如tf、train、Adam、Optimizer、learning_rate、Grad、ient、Des、cent、…等斷詞,都能自動組合為一連串且有順序的序列,以接續自動完成尚未完成的程式碼行編寫。
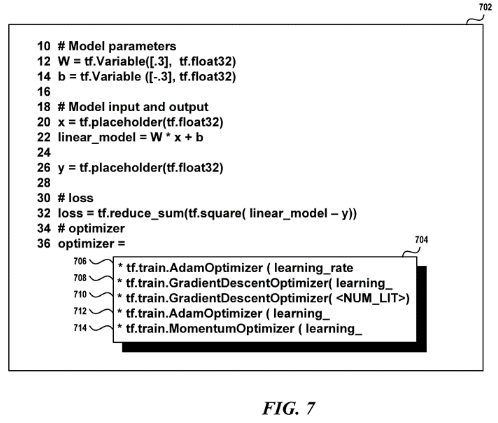
圖4、在IDE介面上偵測到「=」而彈出候選清單(標號704)之示意圖
微軟的‘984專利相較於習知的程式碼行自動完成功能而言,其最大的特色在於,它可以從程式碼之間的邏輯關係而自動推論出,開發人員可能會用到的程式碼提示或建議,並且自動幫忙補齊之後一長串的相關函數、變數、方法、關鍵字或引數等程式碼編寫,而且準確度還很高。微軟的‘984專利主要的貢獻在於,過去幾年很多開發人員只能天馬行空的想像,是否有一天也能靠AI協助他們撰寫程式碼,沒想到生成式AI居然已能實際應用在具有高難度的自動生成程式碼這樣的場景,因此可預期未來生成式AI不僅可自動生成程式碼,也許反過來還能「指導」科學家或工程師導出更具實際應用價值的演算法,以解決當今許多亟待解決的問題,例如資訊安全、病毒變種、氣候異常、癌症醫療等攸關民生但始終迄無最佳解決方案之重要議題。
101專利標的適格性議題
其實,微軟的’984專利主要還是AI演算法,而演算法的專利申請相較於一般的實體裝置、系統而言,通常會先面臨到因美國專利法第101條[13]專利適格性問題而遭核駁。由於AI相關專利常以演算法為中心,此類專利申請範圍,在專利審查機關或在法院專利維權過程中,常面臨適格標的之挑戰而遭遇障礙,為鼓勵AI科技產業之發展,防範許多AI申請動輒於第一回合即中箭落馬,故美國專利商標局(USPTO)於2019年1月,發布修訂專利適格標的指南(2019 Revised Patent Subject Matter Eligibility Guidance)、並於同年10月再頒專利適格指南更新(PEG: Patent Eligibility Guidance Update)[14] ,該指南導引如何使AI相關技術具適格性,其揭示之專利申請策略影響深遠,將增加AI相關發明獲得專利之機會。依該指南原則:Step 2A Prong 2探究是否「整合到一項實際應用」(integrated into a practical application)之中,Step 2B則確定是否存在發明概念(inventive concept),二者之一如肯定,則即便請求項指涉抽象概念,也不會落入不適格之情況[15]。
微軟這篇’984專利請求項的權利保護範圍,正是在習知的程式碼編輯器上,新增一具有注意力機制之Transformer模型的演算法技術特徵,透過應用該特徵而整合自然語言處理;’984專利之所以能克服101條專利適格性,就是將具有注意力機制的Transformer模型,甚至於根據所產生不同斷詞的機率,而能轉化到程式碼編輯器上自動生成程式碼撰寫、註解等實際應用,而使之具有專利適格性[16]。
小結
微軟的「多語言程式碼行自動完成系統」專利,就像是「讀心術」一般,能讀懂軟體開發人員的心思,其技術的本質正是基於Google的Transformer模型架構而設計,只不過微軟進一步將其應用鎖定在程式碼的自動生成。相較於傳統的程式碼行自動完成功能,’984專利顯然更能理解多行程式碼之間的上下文涵義,因而能夠提供更準確、更彈性地協助開發人員完成程式碼的撰寫。此外,透過Transformer模型的訓練後,可支援多種程式語言的語法結構與邏輯,具有相當好的通用性。最後,可能令大家感到好奇的是,微軟的「多語言程式碼行自動完成系統」之專利是否對應到Copilot產品上的某一項功能?據市場消息,Copilot產品賣得還不錯,那麼身為自注意力機制的Transformer模型原創者Google,競爭態勢下難道仍會無動於衷嗎?(狹路相逢勇者勝 -- Google會用其Transformer專利控告ChatGPT?) (5408個字;圖4)
註解:
[2] 同一專利族中的所有專利家族的成員共同擁有一個或共同擁有幾個優先權,這樣的專利家族就被稱為簡單同族專利。
[3] “Attention Is All You Need”, submitted on 12 Jun 2017 (v1), last revised 24 Jul 2023 (this version, v6)
[4] Forbes, “Can Google Challenge OpenAI With Self-Attention Patents”, website:
https://www.forbes.com/sites/alexzhavoronkov/2023/01/23/can-google-challenge-openai-with-self-attention-patents/?sh=1dcac6735639
[5] https://patents.google.com/patent/US11262984B2/en?oq=US+11262984
[6] 開發人員於程式碼編輯器或整合開發環境(IDE)進行程式碼逐行撰寫過程中,若該行程式碼還不是一個合法的語法結構(指違反程式語言的語法邏輯架構),那麼該行程式碼就會被稱為「部分形成的程式碼行」,待開發人員進一步完成或修正後,才算真的完成該程式碼行的撰寫。
[7] 在計算機科學中,"line-of-code"可翻譯成「程式碼行」或「代碼行」,其係指原始碼(source code)在程式碼編輯器或IDE中的單行程式碼。
[8] 在計算機科學中,token有多種不同的意思,完全視應用情境而定,例如:
(1)程式碼中的token:原始碼的基本單位,它可以是函數、變數、方法、關鍵字或引數。
(2)自然語言處理中的token:可以是單詞、子單詞、字元、分隔符、標點符號等元素,常用於文本探勘的切詞和語言模型訓練。
(3)身份驗證中的token:在網路安全和身分驗證中,token是一種用於確認使用者身份或授權的安全憑證,可以是數位密鑰、存取權杖(access token)或其他形式的識別字串。
(4)區塊鏈中的token:代表數位資產或代幣,例如比特幣就是一種token。
以微軟在本專利所提到的token來說,只有(1)和(2)兩種應用情境。
[9] 一般的自然語言是無法直接被電腦識別,要讓電腦能識別自然語言就必須透過編碼將其轉換成數值型向量,此程序就稱為「詞嵌入」。
[10] 傳統的自然語言處理無法記憶文本中各單詞的位置以及位置彼此間的關聯性,然而Google透過一些數學技巧去記憶各單詞的相對位置、權重與彼此間的關聯性,進而提升推理能力,此程序就稱為「位置嵌入」。
[11] 如何斷詞的方法有很多,視使用的編碼演算法而定,此處token後的數目是為了說明方便。
[12] 基於專利與AI技術之複雜性,所以此處盡量不直接從獨立項的描述直譯,以免落入陌生的專利語言之泥淖。
[13] 美國專利法第101條規定專利適格標的(eligible subject matter):任何新穎有用之程序、機械、製造或物質的組合、或任何該等新穎且有用之改良(process, machine, manufacture, or composition of matter)方具專利適格。另依最高法院歷來判例,發展出若干不得授予專利之標的,即所謂之司法例外(judicial exceptions),其包括(1)自然法則;(2)自然/物理現象;(3)抽象概念等,屬於專利不適格(patent-ineligible)之標的,AI演算法一般較易落入抽象概念。
[14] 2019 Revised Patent Subject Matter Eligibility Guidance, 84 Fed. Reg. 4, 51 (Jan. 7, 2019), https://www.govinfo.gov/content/pkg/FR-2019-01-07/pdf/2018-28282.pdf; USPTO於2019年10月再頒更新版:Oct. 2019 Patent Eligibility Guidance Update, 84 Fed. Reg. 202; 另參Emily Rapalino, Cindy Chang & Nicholas Mitrokostas, Patent and Regulatory Challenges in AI’s Use in Life Sciences, July 1, 2020, https://www.medtechintelligence.com/column/patent-and-regulatory-challenges-in-ais-use-in-life-sciences/
[15] 陳家駿 & 許正乾,從美國專利適格標的指南 -- 談AI相關發明審查原則暨近年專利申請重要案例,月旦法學雜誌,320期,202201.
[16] 同理,上一篇Google的’978專利也是因為在習知既有的編碼器與解碼器中,除了新增具有原創性的注意力機制的Transformer模型演算法之外,另透過Q (query)、K (Key)、V (Value) 等向量運算而可以模仿人類理解或推理對話或文本前後的整段話涵意,所以Google的’978專利可克服101條專利適格性問題。
作者資訊:
陳家駿 台灣資訊智慧財產權協會 理事長
許正乾 因子數據股份有限公司 共同創辦人
參考資料:
“Attention Is All You Need”, submitted on 12 Jun 2017 (v1), last revised 24 Jul 2023 (this version, v6)
Can Google Challenge OpenAI With Self-Attention Patents. Forbes, 2023/01/23.
US10452978B2-- Attention-based sequence transduction neural networks
US 11262984B2-- Multi-lingual line-of-code completion system
2019 Revised Patent Subject Matter Eligibility Guidance, 84 Fed. Reg. 4, 51 (Jan. 7, 2019)
USPTO於2019年10月再頒更新版:Oct. 2019 Patent Eligibility Guidance Update, 84 Fed. Reg. 202
Cindy Chang & Nicholas Mitrokostas, Patent and Regulatory Challenges in AI’s Use in Life Sciences, 2020/07/01.
從美國專利適格標的指南--談AI相關發明審查原則暨近年專利申請重要案例。月旦法學雜誌,320期,202201。
相關文章:
1. 蘋果最新專利表明,除了智慧手錶之外,對智慧戒指產生興趣了
2. 谷歌最新專利一旦成真,將成為擊敗iPhone的秘密技術
3. 狹路相逢勇者勝 – Google會用其Transformer專利控告ChatGPT?
4. Google Transformer模型專利 – ChatGPT自注意力機制之重要推手
5. 蘋果最新專利披露其正在研究捲曲式iPhone,而非折疊式iPhone
6. 以ChatGPT撰擬專利可行性評估及其法律風險
--------------------------------------------------------------------------------------------------------------------------------------------
【聲明】
1.科技產業資訊室刊載此文不代表同意其說法或描述,僅為提供更多訊息,也不構成任何投資建議。
2.著作權所有,非經本網站書面授權同意不得將本文以任何形式修改、複製、儲存、傳播或轉載,本中心保留一切法律追訴權利。
|