
Google Transformer模型專利 – ChatGPT自注意力機制之重要推手
科技產業資訊室(iKnow) - 陳家駿、許正乾 發表於 2023年8月3日
圖、Google Transformer模型專利 – ChatGPT自注意力機制之重要推手
這半年多來,OpenAI所開發的ChatGPT聊天機器人在全世界夯到不行,該ChatGPT係指一種基於生成式預訓練轉換模型(Generative Pre-trained Transformer,簡稱GPT),但其中核心關鍵的Transformer模型演算法,卻非OpenAI或微軟自己所原創。最早,是由推出Bard聊天機器人的Google,率先開發出Transformer模型,而該模型係緣自於Google 2017年所推出的原始論文“Attention Is All You Need”[1]而來,之後幾家業者也陸續投入基於Transformer模型為基礎而改良或更進一步的應用,但沒想到OpenAI和微軟在商用上卻青出於藍後來居上,威脅到Google推出的Bard,至於OpenAI和微軟是否用到Google所發表的Transformer模型專利雖有待考證,不過可以確定的是,2022年11月成功發表眾所矚目的ChatGPT,Transformer模型應是其重要推手,得以讓AI邁入新的深度學習技術框架之里程碑,因此本文即揭開Transformer模型背後重要的專利。
話說自從Google的AI研發團隊,於2017年在NeurIPS大會提出Transformer模型,並且描述其在機器翻譯方面高準確度的優異效能後,Transformer模型的相關研究與應用幾乎就以指數型態向上成長,甚至已經取代過去AI領域中,常用到的CNN卷積式神經網路(Convolutional Neural Networks)與RNN遞歸式/循環神經網路(Recurrent Neural Networks)等深度學習模型,特別是在引入「自注意力」(self-attention)的機制後,Transformer模型獲得前所未有且最接近人類的模仿與學習能力,AI終於可以藉由追蹤序列資料中的關係,學習上下文之間的脈絡及意義[2],「理解」(類理解)並記憶長篇大論的文章,而且準確度大為提高許多,顛覆過去只能閱讀短文的缺陷。
OpenAI利用Transformer模型研發出眾所皆知的ChatGPT,其發表是基於GPT-3.5技術,並在5天內突破百萬用戶註冊,而其優越富含人性的對話互動體驗,讓世界看到Transformer模型在未來的發展潛力。2023年3月更推出基於GPT-4為基礎的ChatGPT,且放眼未來研究基於GPT-5的技術,期望達到可擴展性(如透過增加模型規模和參數,以更加擴展自然語言處理能力)、安全性(如降低大語言模型可能帶來的不實資訊)、可解釋性(如提高模型的可解釋性,讓人類更好理解AI技術的應用模式)。
基於以上所提的transformer、generative、attention等技術關鍵字,搜尋到Google一篇名為「Attention-based sequence transduction neural networks」(基於注意力序列轉導神經網路[3]),並在2019年10月22日獲准案號為US 10,452,978 B2(以下稱本專利)的美國發明專利[4],而其申請日為2018年6月28日,從申請日到獲准日也才僅18個月,可見其創新度之高很快被審查委員肯定。此外,本專利目前之簡單同家族專利數量38件並分佈在13國家,而被引用專利數量為55件(包含已獲證與其獲證之前的申請案),可見Google的內部的決策高層,對該技術的未來發展有多重視。
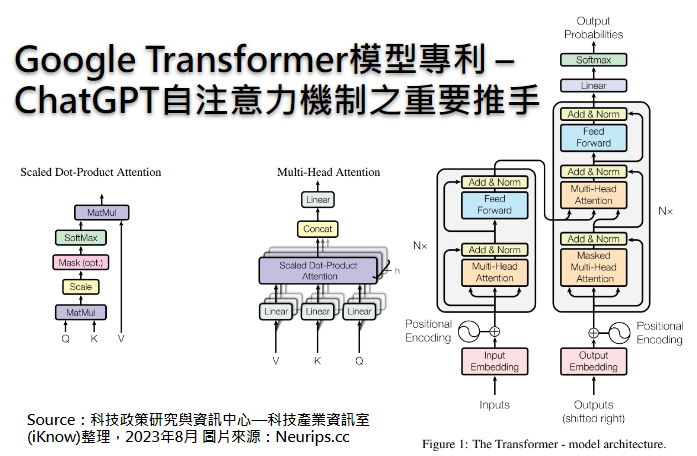
圖1為本專利Transformer模型的代表圖,其獨立項1揭露一種系統(標號100),包含一或多個計算機與一或多個用以儲存指令的儲存裝置,透過該等計算機執行指令,實現一以基於注意力之神經網路(attention-based neural network,標號108),其用以將一輸入序列(標號102)轉導[5](transduction)為一輸出序列(標號152),其中該注意力神經網路(標號108)又包含一編碼神經網路[6](encoder neural network,標號110)、該編碼神經網路包含多個編碼子網路(encoder neural network,標號130),各該編碼子網路(標號130)包含一編碼自注意力子層(encoder self-attention sub-layer,標號132),以及一解碼神經網路[7](decoder neural network,標號150)。
圖1 本發明Transformer模型的代表圖
通常獨立項可能隱含著一件發明專利的主要技術特徵,也是專利申請人經過幾次與審查委員來回答辯、檢索與調校,最後基於專利法而達成某種共識的一種技術保護範圍,所以針對獨立項1,現在就拆解本專利Transformer模型之比較重要的技術元件來分析說明。
編碼神經網路/解碼神經網路
概括來說,本專利是透過編碼神經網路(標號110)接收輸入序列(標號102)後,再經由注意力神經網路(標號108),對輸入序列(標號102)進行計算機可以識別的編碼,並轉導成另一種形式的表示法,最後透過解碼神經網路(標號150)將其轉換為前述的輸出序列(標號152),其實這就是AI即時翻譯的原理。舉例來說,針對中文翻譯成英文,若輸入序列(標號102)為中文標題「轉換模型超越過去的RNN」,透過注意力神經網路之轉導,就可以快速翻成英文標題“Transformer Model Beyond Traditional RNNs”。
為何需要編碼神經網路(標號110)與解碼神經網路(標號150)?對於計算機系統而言,它們是無法讀取「轉換模型超越過去的RNN」這樣的一段純文字內容,因為在計算機系統的世界中,只能讀取數值型態的向量,例如「轉換」一詞可能就被編碼神經網路(標號110)編碼成[0, 0, 0, 1, 1, 0, 1, 1]這樣的數值型向量而讓計算機系統讀取;同理,「模型」一詞就可能被編碼成[1, 0, 1, 0, 0, 0, 0, 1],其餘依此類推。
以上經過編碼後,可讓原本計算機系統無法讀取的資料型態,轉換為可讀取的數值型資料,此程序稱為「詞嵌入」[8](word embedding),其嵌入方式可透過One-Hot encoding、Word2Vec、Glove等演算法得到。接著,「轉換模型超越過去的RNN」這樣的一段純文字被編碼後,再經由注意力神經網路(標號108)的複雜數學運算,能轉導成英文的“Transformer Model Beyond Traditional RNNs ”。此外,編碼神經網路(標號110)與解碼神經網路(標號150),本身也擔任提取特徵的工作以降低資料維度,其功能類似機器學習中大家耳熟能詳的PCA主成分分析(principal component analysis)。
到目前為止,這些都是習知的編碼器與解碼器處理文字或語音的方式,只有這些還不足以讓AI「聰明地」閱讀長篇大論的文章,或「理解」語義並與人類互動對話。因此,本專利在編碼神經網路(標號110)內,增加一「嵌入層」或稱「輸入嵌入」(embedding layer或input embedding,標號120)以執行一種「位置嵌入」(positional embedding,圖1中未標號)的數學技巧。
位置嵌入(positional embedding)
Google在本專利明確提及,透過「嵌入層」(embedding layer或input embedding,標號120)執行位置嵌入的技巧,就可擺脫過去使用RNN或CNN等神經網路架構。
圖1中的「輸入嵌入」(input embedding,標號120),接收到如「轉換模型超越過去的RNN」這樣的輸入序列(標號102)之純文字內容後,將該純文字內容予以詞嵌入,也就是說,此時的「轉換模型超越過去的RNN」中的每個單詞,已被轉換成計算機系統可讀取的數值型態的向量。更甚者,本專利的技術特徵之一就是透過位置編碼(positional encoding,圖1中的紅字),進行「位置嵌入」(positional embedding)的數學技巧,好用以記憶各單詞的相對位置、權重與彼此間的關聯性,進而提升推理能力。Google在本專利中還特別強調,「位置嵌入」可透過sin和cos兩個函數,表示為下列的二個數學式:
其中,PE表示「位置嵌入」(positional embedding), pos為位置, i 為位置嵌入的維度, dmodel為嵌入大小。這邊就暫不討論複雜的數學,不過Google在本專利中提到這二個數學式,可以讓Transformer模型在冗長的序列中作出很好的語言推理,並可廣泛應用在許多場景中。
「位置嵌入」的設計在Transformer模型中扮演重要角色,不僅可以在長篇大論中記住重要單詞的相對位置,而且可計算出所有單詞之間的關聯性與權重,進而產生推理能力,這樣的數學技巧,在自然語言處理的技術中顯得格外重要。
自注意力機制(self-attention mechanism)
Transformer模型於本專利之獨立項中,其最重要的技術特徵就是「自注意力機制」,也可以說是Transformer模型的靈魂。注意力機制並不好理解,這裡先科普一下自注意力機制的目的是什麼?為何它這麼重要?茲先從實際例子說明或許更容易捕捉其迷人之處。
其實所謂的「自注意力」(self-attention),其涵意從字義上即可略知一二,就是從在學習過程中自己「注意」重要的事物。舉例來說,若出現一句英文為:
The Transformer model is a deep learning model that adopts self-attention mechanism, and it is mainly used in the fields of Natural Language Processing (NLP) and Computer Vision (CV).
透過引入自注意力機制,就能知道文中的「it」是指“The transformer model”,而“self-attention”就是用來描述“The transformer model”,係採用自注意力機制的一種深度學習模型。在深度學習中,自注意力是一種用於處理序列資料的技術,舉凡句子、影片片段或任何具有時間序列特性的資料都能應用的上。在這種技術中,Transformer模型不僅專注於處理序列中的各單詞(或稱元素),而且還能自動捕捉序列中各單詞之間的關聯性和重要性。以這一句英文來說,透過自注意力機制會給予The transformer model、it、self-attention較高的權重與關聯性,然後特別「關注」。若再更進一步刻意將前述英文改成以下:
The Transformer model is a deep learning architecture that utilizes a self-attention mechanism. It differs from RNN model, and it is limited to shorter sequences.
藉此測試ChatGPT對於英文翻譯成中文的理解能力,特別是Transformer模型對於二個it的理解,其測試結果如圖2所示。
圖2 測試Transformer模型對於兩it的理解
測試結果發現,第一個it當然指得是The Transformer model,而第二個it明確指出就是RNN模型,而不是只單純地直譯成「它」,可見ChatGPT可以「理解」整段話的意思。這就是自注意力機制的強項。
以上所述的工作,都揭露在本專利中Google提出的自注意力機制架構,如圖3所示。這些自注意力,都在圖1中“Multi-Head Attention”(標號132、174)與“Masked Multi-Head Attention”(標號172)進行Q(query)、K(Key)、V(Value)向量運算,因涉及複雜的數學就不在此討論。關於圖3架構的演算法如何執行自注意力機制,Google並未在本專利全部揭露,有興趣的讀者可參考前述Google的原始論文“Attention Is All You Need”。
不過吾人可以用簡單的口訣「問、答、解」,來分別幫助理解Q (query)、K (Key)、V (Value)的作用。再繼續以「轉換模型超越過去的RNN」為例,當接收到輸入序列為「轉換模型超越過去的RNN」時,首先針對單詞「轉換」予以「詞嵌入」(即編碼為一種數值型態的向量),然後再分別進行:
(1) Q (query):在閱讀到「轉換」一詞時,會詢問「轉換」究竟代表何意?
(2) K (Key):根據Q (query)判斷輸入序列的其他位置,對於應答當下的「轉換」有哪些單詞比較重要,例如模型、RNN、天氣、專利、股市、…等許多選項,都是有可能影響「轉換」的真實意思。
(3) V (Value):最後Q(query)針對K (Key)的許多選項一一評分,認為模型與RNN是最可能直接影響「轉換」的意思,所以評分完成後給出一個明確的最佳解,最後將「轉換」翻譯為“transformer”,而非conversion、transfer、change、switch這些單詞。
上圖係原專利之圖,但因略模糊所以再用下圖補充(但無標號)
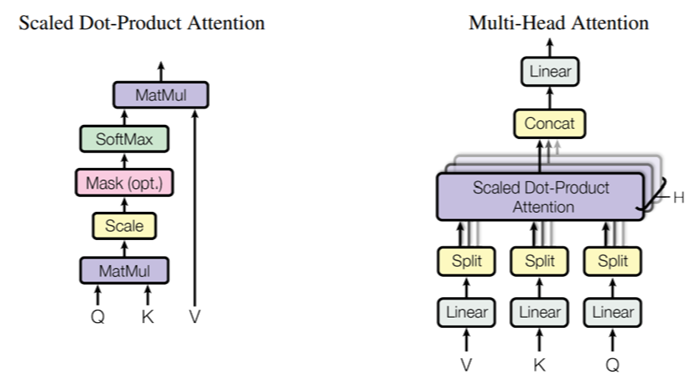
圖3 本專利提出的自注意力機制架構
softmax函數
對應本專利圖1的“softmax layer”(標號190),用以產生softmax函數。softmax函數在神經網路中的輸出層,是一個計算簡單但很重要的函數,softmax函數的作用,就是大家常戲稱ChatGPT是一直在玩的「文字接龍」,因為其背後的原理正是經由資料被正規化(normalized)後,形成某一種機率分佈,而該機率分布就是用來估測每個類別的機率預測。
舉例來說,當輸入序列為中文的「轉換模型超越過去的RNN」時,由於中文句子的最後是深度學習中的常用名詞RNN,而且句子中也出現「超越」這樣的動詞,因此自注意力機制透過前述的Q (query)、K (Key)、V (Value)作用後,推測出「轉換」應該有很大的機率必須譯為transformer,而非conversion、transfer、change、switch這些單詞,最後就透過softmax函數決定將transformaer予以輸出。
最後,總結一下本專利的重點:
(1) Transformer模型加入自注意力機制,可使一輸入序列被轉導至一輸出序列,不僅計算速度加快,而且推理能力提升不少,有別於以往的RNN,所以在機器翻譯和語言辨識上獲得更好的效果。
(2) 位置嵌入與自注意力機制的引入,可在冗長的輸入序列中做出很好的語言推理。
(3) 本專利源自Google發表的原始論文“Attention Is All You Need”,不論專利或論文,其被引用次數都相當多,可見其影響力之深遠。
Google v. OpenAI/微軟- -潛在之專利衝突
在六大高科技強權Apple/Amazon/IBM/Google/Meta/Microsoft中,彼此間互告的美國專利訴訟,其實相對不多!但這次在聊天機器人方面,Google微軟兩強相遇,雖然首發由Google的轉換模型拔得頭籌取得專利,可是不料竟然被微軟和OpenAI超車,在第一回合角力中大放異彩領先群雄,這當然讓Google情何以堪!而既然ChatGPT係根據Transformer應用創出,因此理論上當然不排除可能踩到Google的IP,假如檢視後發現其落入專利之申請範圍,則Google是否會對微軟等提告,引起高度關切,敬請期待本刊下一篇文章:狹路相逢勇者勝 -- Google會用其Transformer Self-Attention專利控告ChatGPT嗎?(4691個字;圖3)
註解:
[1] “Attention Is All You Need”, submitted on 12 Jun 2017 (v1), last revised 24 Jul 2023 (this version, v6)
[2] 何謂Transformer模型?2022年6月21日 NVIDIA, https://blogs.nvidia.com.tw/2022/06/21/what-is-a-transformer-model/
[3] “transduction”翻成中文是「轉導」或「轉換」,指將一種形式或訊號轉換成另一種形式或訊號的過程。
[5] 轉導一詞具有「將某一物件轉換至另外一種形式」之意,在Google的本專利中也多次提到「序列轉導 (sequence transduction)」,指的就是輸入一段文字或語音序列後可轉換為另一種形式的表示法而被輸出,即時翻譯就是典型的序列轉導行為。
[6] 本專利中的編碼神經網路,其實就是一般人所熟知的「編碼器」。
--------------------------------------------------------------------------------------------------------------------------------------------
【聲明】
1.科技產業資訊室刊載此文不代表同意其說法或描述,僅為提供更多訊息,也不構成任何投資建議。
2.著作權所有,非經本網站書面授權同意不得將本文以任何形式修改、複製、儲存、傳播或轉載,本中心保留一切法律追訴權利。
|