
IBM新儲存技術設計新AI晶片、比GPU效能高出280倍
科技產業資訊室 (iKnow) - 黃松勳 發表於 2018年6月19日
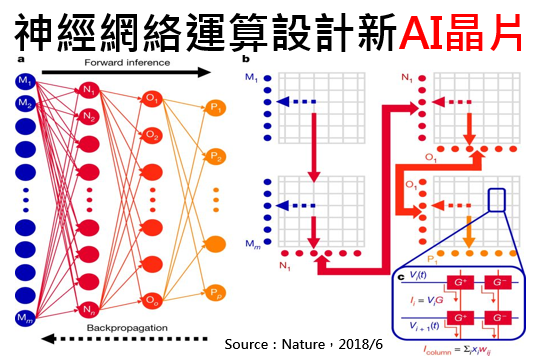
圖、將完全連接的神經網絡映射到NVM陣列上
雖然GPU的導入,在AI領域已經取得蓬勃的發展,但這些晶片仍然將處理和儲存分開,表示在處理與儲存之間的數據傳輸過程,仍需要耗費大量的時間和效能。這促使著研究人員對於新的儲存技術進行研究,讓數據的儲存和處理可以在相同的位置上,進而提高運算的速度和能源效率。
利用新型儲存裝置以類比方式的連續比例調整電阻值作為數據儲存,而非數位方式1和0來儲存數據。由於訊息儲存在儲存單元的電導中,因此可以透過簡單的將電壓傳遞到所有系統來進行物理性計算。但是這些裝置存在著本質的物理缺陷,使得其表現出的行為結果會產生不一致,表示著,若嘗試使用它們來訓練神經網絡,則會導致其分類精確度會低於目前使用GPU的結果。
因此,研究人員透過創建”突觸細胞”來解決這個問題,每個突觸細胞對應於網絡中的每個神經元,這些神經元具有長期和短期記憶。每個細胞由一對相變儲存器(PCM)單元以及三個電晶體和一個電容器所組成,相變儲存器(PCM)將權重數據儲存於其電阻之中;而電晶體與電容器的組合,則作為儲存數據的電荷。
PCM是一種”非揮發性記憶體”,能在沒有外部電源的情況下,依然保留著儲存的資訊;而電容器是”揮發性(易失性)”的,因此只能保持幾毫秒的電荷。但電容器沒有PCM裝置的可變性,因此可以快速準確地進行編程。當對網絡進行圖像訓練以完成分類任務時,只有更新電容器的權重。在看過幾千張圖像後,權重數據被傳送到PCM單元作為長期儲存。
為了測試他們的設備,研究人員在一系列流行的圖像識別基準上訓練了他們的網絡,實現了精確度與Google所領導的神經網絡軟體TensorFlow相媲美。但重要的是,他們預測完成建構的晶片,將比GPU效能高出280倍,並且實現在相同單位面積的操作中,擁有100倍的運算能力。
雖然,目前研究人員還未建構出真正晶片,只有PCM元件實際上被用來做測試,其他組件則為電腦模擬出來的。而最終的晶片將被設計成可以與GPU協作,處理完全連接層的運算,也可同時處理其它任務,使其能夠廣泛地被應用。
未來的神經網絡晶片有兩個主要應用:一是將AI導入個人裝置,並使數據中心效率更高;二是降低大型公司伺服器在電費帳單上的大筆費用。
結語
以目前的GPU效能來說,雖然已超越了CPU的運算效能,但其數據儲存與運算處理仍無法在同一點上操作,所以整體的運算效能提升還是相當有限。PCM元件的出現,解決了長程記憶儲存的問題,若能在GPU上加入PCM元件,則可大幅降低數據處理與儲存轉換的時間和能量,相對的,其效能與速度則會有相當幅度的提升。對於未來大量的AI神經網絡運算應用於各種產業,新晶片的設計融入GPU中或生產出新的AI晶片,將扮演著其能否大量普及化的關鍵。
(1119字;圖1)
參考資料:
This New Chip Design Could Make Neural Nets More Efficient and a Lot Faster. Singularity Hub,2018/6/11
Equivalent-accuracy accelerated neural-network training using analogue memory. Nature,2018/6/6
本站相關文章:
1.IBM的深度學習獲得重大突破,縮短時間提高效率
2.競逐AI晶片誰將勝出?
3.2018年將是新概念AI晶片崛起之時
4. IBM大筆投資人工智慧
5.IDC:中國大陸AI 晶片GPU加速運算市場至2021年成長率達70.5%
--------------------------------------------------------------------------------------------------------------------------------------------
【聲明】
1.科技產業資訊室刊載此文不代表同意其說法或描述,僅為提供更多訊息,也不構成任何投資建議。
2.著作權所有,非經本網站書面授權同意不得將本文以任何形式修改、複製、儲存、傳播或轉載,本中心保留一切法律追訴權利。
|